Closing the Backup Loop: A Custom Controller for Longhorn
New PVCs were silently unprotected until I noticed. I built a label-driven controller to close the loop — jobs created automatically, violations alerted, archives handled.
Introduction
Every time I deployed a new workload on Bletchley, I had the same nagging thought: did I remember to create a backup job for that PVC? The answer was usually yes — eventually. But "eventually" is not a backup strategy. The Grafana volume had been running for weeks before I manually created its first recurring job. The Alertmanager PVC sat unprotected until I noticed it. The process was slipping, and I knew it.
The fix was obvious in principle: automate it. But Longhorn's recurring jobs are cluster-level CRDs in longhorn-system, not something you can drive from a Helm values file or a simple CronJob. What was needed was a controller — something that watches for PVCs, reads their intent from labels, and creates the right backup job automatically. Something that also notices when things go wrong and says so.
So I built one. This post covers the design decisions, the implementation, what broke during testing, and the four bugs that the shakeout found and fixed. The code is on GitHub at vluwte/longhorn-backup-controller — MIT licensed, ARM64 tested, ready to adapt.
🏠 This is part of the Homelab Journey series - building a production Kubernetes cluster from scratch.
- Secret Management Part 4
- Closing the Backup Loop: A Custom Controller for Longhorn (you are here)
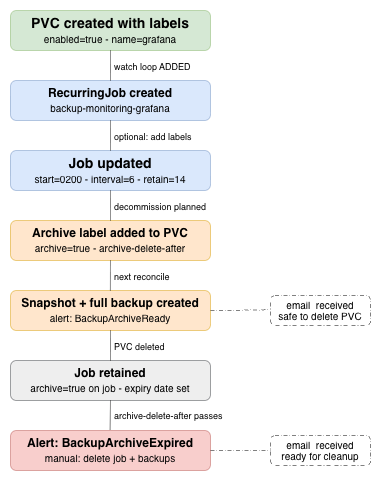
The problem with manual backup jobs
Longhorn recurring backup jobs are straightforward to create in the UI. You give them a name, a cron schedule, a retention count, and assign them to a volume. The problem is that nothing creates them for you. Every new PVC is silently unprotected until a human notices and acts.
In my cluster that meant four manual jobs with auto-generated names (c-1pcj37, c-a2n71k, c-afuh2t, c-lsv43w) — opaque, inconsistently scheduled, and with no obvious connection to the volumes they protected. When I restored the Grafana volume from backup and recreated the PVC, it got a new UID — but I only noticed the stale job association weeks later. When I deployed Alertmanager and OpenBao, both sat unprotected while I was busy with other things.
The right answer was a controller that closes the loop: new PVC appears with labels → backup job exists within seconds. No human required.
The label schema
The first design decision was how to express backup intent on a PVC. The answer was Kubernetes labels — the native pattern for attaching metadata that tools can read.
Two labels are always required:
backup.vluwte.nl/enabled: "true" # or "false"
backup.vluwte.nl/name: "grafana" # used to construct the RecurringJob name
The enabled label is the compliance signal — every Longhorn-backed PVC must have it, either opting in or out. Missing it entirely is an alert condition. The name label becomes part of the RecurringJob name: backup-<namespace>-<name>. So a PVC in monitoring with name: grafana produces backup-monitoring-grafana — immediately readable in kubectl get recurringjobs.
Five optional labels override cluster-wide defaults when present:
backup.vluwte.nl/retain: "8"
backup.vluwte.nl/interval: "4" # hours — restricted to divisors of 24 to keep schedules predictable
backup.vluwte.nl/start: "0030" # HHMM format — see note below
backup.vluwte.nl/full-backup-interval: "4" # every Nth run is a full backup
backup.vluwte.nl/concurrency: "1"
One gotcha discovered during testing: backup.vluwte.nl/start must use HHMM format — 0030, not 00:30. Kubernetes label values must match ([A-Za-z0-9][-A-Za-z0-9_.]*)?[A-Za-z0-9] — colons are not in that character set and kubectl label rejects them outright. The controller enforces HHMM and generates the cron expression from there. Longhorn uses Quartz-style 6-field cron — with seconds support and ? for day-of-week, not standard 5-field cron — so start 0030 + interval 4 produces 30 0/4 * * ?.
The cluster defaults — retained in a ConfigMap in the backup-controller namespace — are what every PVC gets if it doesn't override:
| Label | Default |
|---|---|
retain |
8 |
interval |
4 hours |
start |
0030 |
full-backup-interval |
4 |
concurrency |
1 |
Change the ConfigMap, restart the controller, and every PVC using defaults inherits the new value on the next reconcile.
In practice, labelling a PVC looks like this:
# Opt in with cluster defaults
kubectl label pvc my-pvc -n my-namespace \
backup.vluwte.nl/enabled=true \
backup.vluwte.nl/name=my-app
# Override specific defaults
kubectl label pvc my-pvc -n my-namespace \
backup.vluwte.nl/start=0200 \
backup.vluwte.nl/interval=6 \
backup.vluwte.nl/retain=14
# Opt out — no job created, no alert
kubectl label pvc my-pvc -n my-namespace \
backup.vluwte.nl/enabled=false
# Prepare for intentional removal
kubectl label pvc my-pvc -n my-namespace \
backup.vluwte.nl/archive=true \
backup.vluwte.nl/archive-delete-after=2026-07-11
The controller
The controller is a single Python process running as a Deployment in its own backup-controller namespace. It has one responsibility boundary: read PVC labels, manage RecurringJobs, expose metrics.
It runs in two modes simultaneously:
Watch loop — streams PVC events from the Kubernetes API. When a PVC is added or modified, the controller reads its labels and immediately creates or updates the corresponding RecurringJob. When a PVC is deleted, it removes the managed job (unless the PVC has an archive label — more on that below).
Full reconcile — runs on startup and on every watch reconnect (every 5 minutes). Does a complete pass over all Longhorn-backed PVCs, reconciling any that the watch loop may have missed. This is the "catch everything" safety net.
All operations are idempotent: the controller compares desired vs actual state and patches only when needed. Running the reconcile repeatedly produces no side effects.
The controller never talks to Alertmanager directly. It exposes a /metrics endpoint on port 8080 that Prometheus scrapes. Prometheus evaluates alerting rules against those metrics. Alertmanager handles routing. The controller stays stateless with respect to alerting — it just tells the truth about what it sees.
Every managed RecurringJob gets three labels that the controller uses for ownership tracking:
backup.vluwte.nl/managed: "true"
backup.vluwte.nl/source-namespace: "monitoring"
backup.vluwte.nl/source-pvc: "grafana"
Only managed jobs are touched by the controller. Manually created jobs are left entirely alone.
It is worth being explicit about how Longhorn backup scheduling actually works. RecurringJobs are defined centrally in longhorn-system, but volumes opt into them via a label on the Longhorn Volume CR. The controller ensures both that the job exists and that the volume references it — creating the RecurringJob in longhorn-system and patching the corresponding Volume CR with the association label.
One implementation detail worth noting: the controller reads the volume name from spec.volumeName on the PVC rather than deriving it as pvc-<pvc-uid>. While often equal, this is an implementation detail of Longhorn and not guaranteed — after a volume restore, the PVC is recreated with a new UID while the Longhorn volume keeps its original name. Using spec.volumeName handles both cases correctly. This surfaced when labelling the Grafana PVC — it had been restored in the Backup Validation Post and the UID mismatch had gone unnoticed until then.
Metrics and alerts
The controller exposes per-PVC labelled gauges so Alertmanager alert messages name the exact PVC at fault — no lookup required.
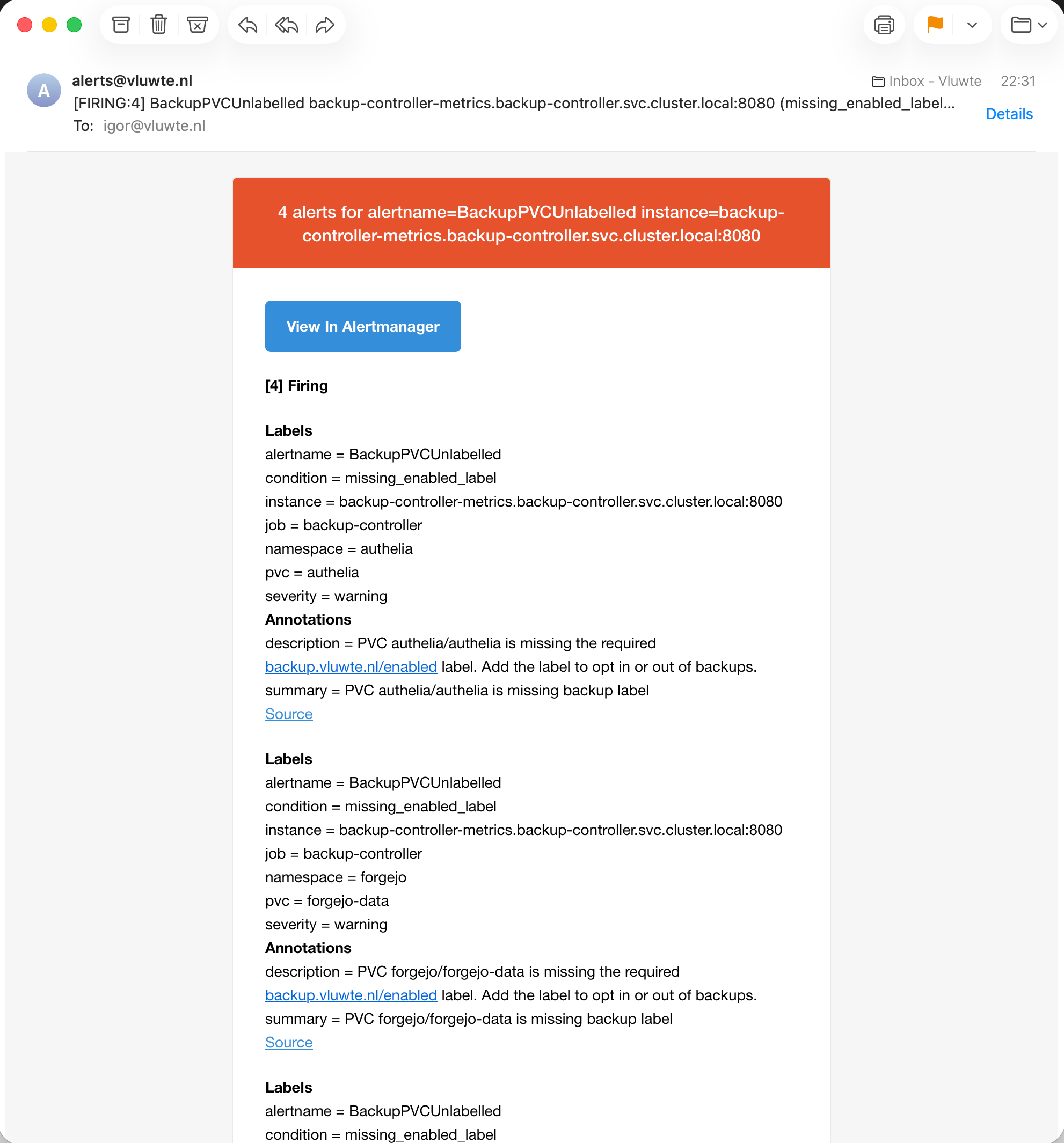
backup_pvc_violation{condition="missing_enabled_label",namespace="authelia",pvc="authelia"} 1.0
backup_pvc_managed{job="backup-monitoring-grafana",namespace="monitoring",pvc="grafana"} 1.0
Four conditions trigger alerts, all routed via Prometheus rules to Alertmanager. For the duplicate name condition, the controller refuses to manage either PVC until the conflict is resolved — both are flagged as conflicting and neither gets a backup job.
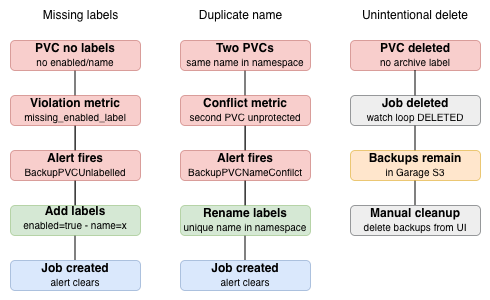
The archive workflow
The most interesting part of the controller is what happens when you intentionally remove a PVC. A simple delete would leave the managed job orphaned and any existing backups frozen — no new backups, no cleanup, and no one would know.
The archive workflow closes that gap. Before decommissioning a workload, you label the PVC:
kubectl label pvc grafana -n monitoring \
backup.vluwte.nl/archive=true \
backup.vluwte.nl/archive-delete-after=2026-07-11
On the next reconcile, the controller detects the archive label and triggers a two-step process: first it creates a Longhorn snapshot, then creates a backup from that snapshot. Longhorn handles incremental vs full internally — the controller just triggers the backup and waits for completion. When the backup completes, backup_archive_ready fires and an alert email arrives:
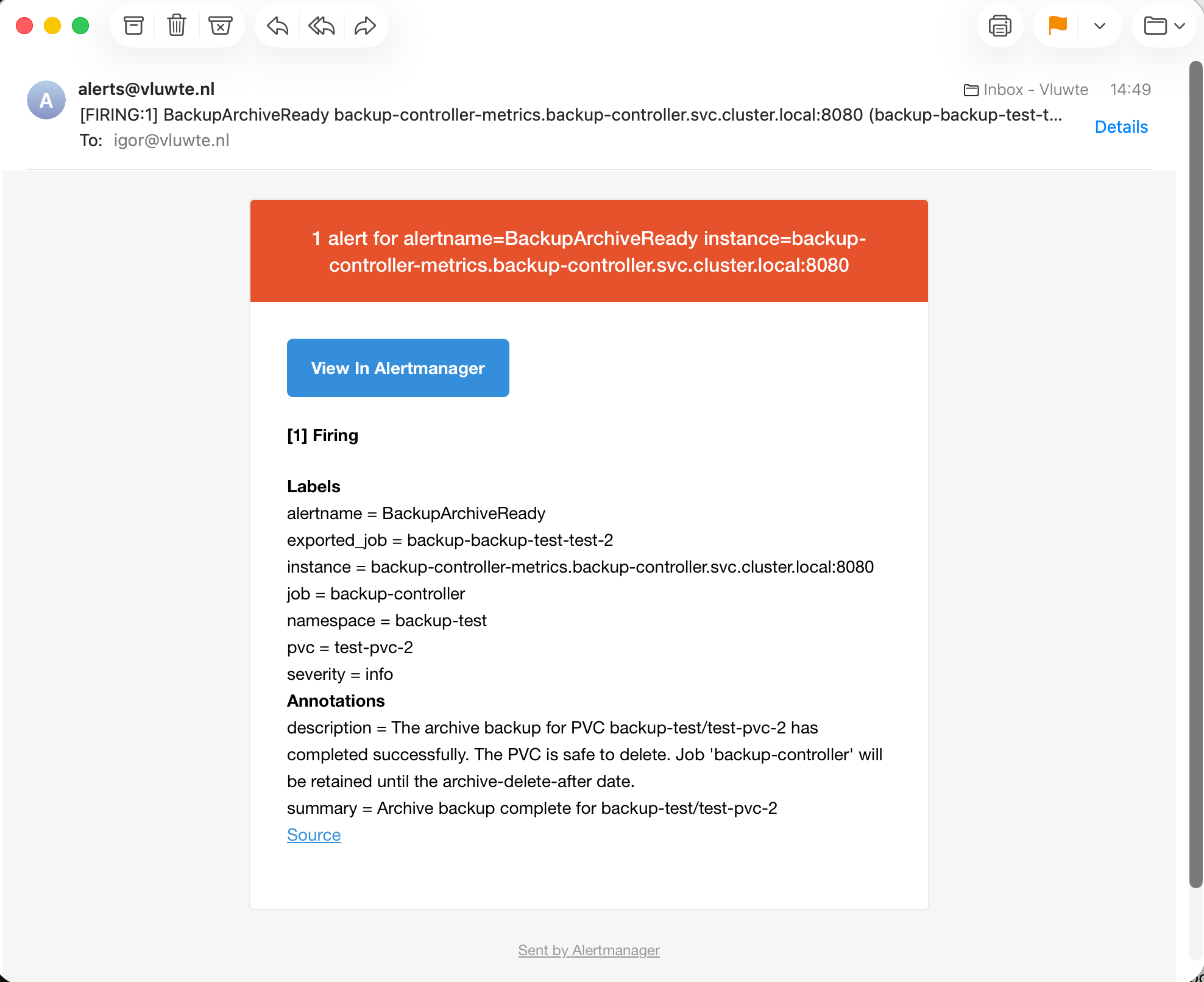
After deleting the PVC, the managed job is retained — not deleted. The controller detects that the PVC is gone but sees archive=true on the job (copied there when the snapshot was created) and leaves it in place. The full reconcile reports it as retained, not orphaned.
When the archive-delete-after date passes, backup_archive_expired fires:
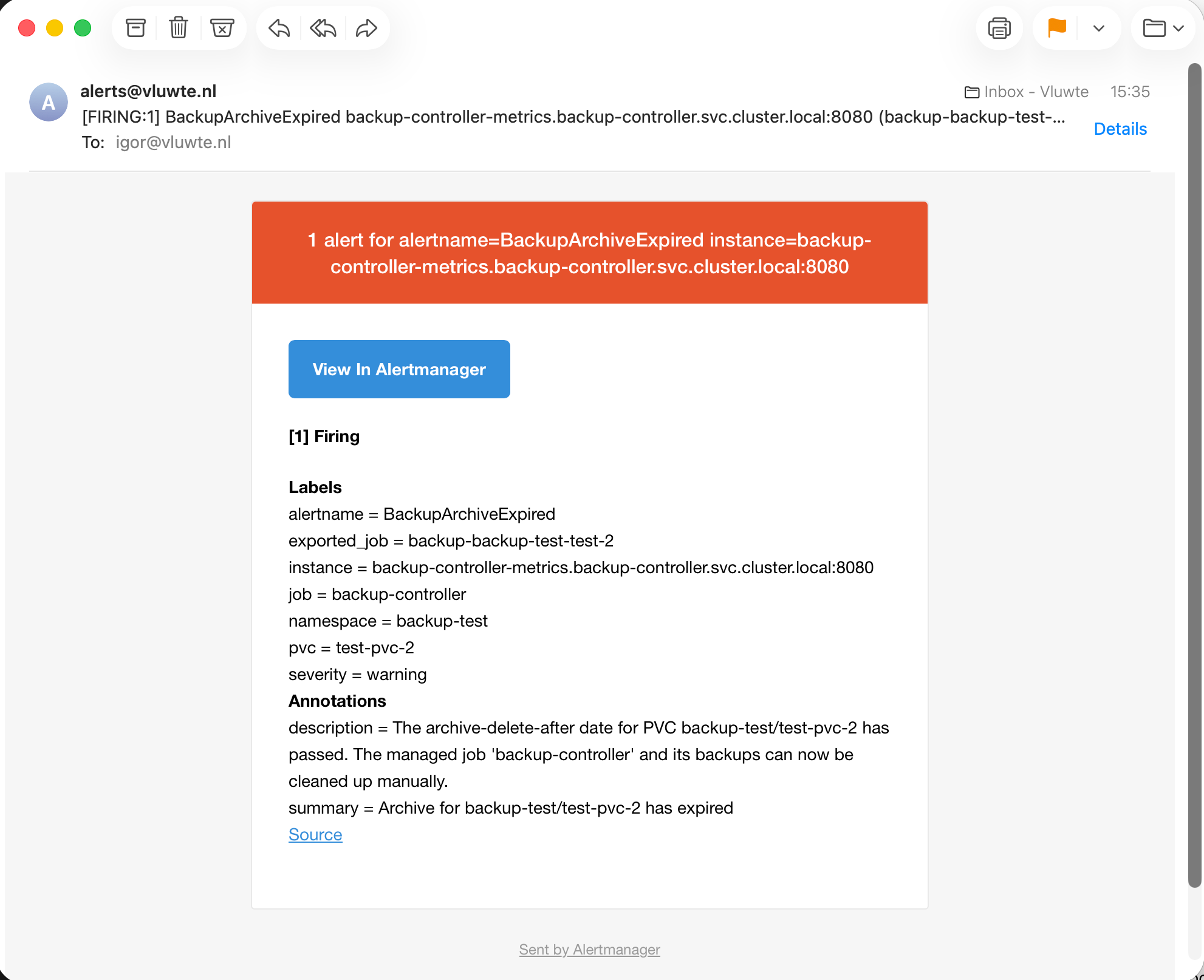
The final deletion — removing the job and the backups from Garage S3 — is intentionally left as a manual step. When it comes to destroying data, even expired archives, I want final control. The alert is the signal; the action is mine.
What happens after a restore
One behaviour worth highlighting explicitly: after restoring a volume and creating a new PVC in Longhorn, the controller immediately flags it as unlabelled.
[event] ADDED backup-test/restored-grafana
[violation] backup-test/restored-grafana: [missing_enabled_label] ...
An alert email arrives within minutes. This is the controller closing the backup loop after a restore — a restored volume is not automatically protected. Re-apply the labels and the job is created:
kubectl label pvc restored-grafana -n monitoring \
backup.vluwte.nl/enabled=true \
backup.vluwte.nl/name=grafana
The alert clears, the job appears, backup coverage is restored.
Shakeout: what broke and what was fixed
Before declaring the controller production-ready, I ran a structured shakeout across twelve test scenarios. Four bugs were found and fixed.
Bug 1 — Volume label deferred on new PVCs. When a PVC is created, the watch loop fires immediately. At that moment spec.volumeName is empty — Longhorn hasn't bound the volume yet. The controller was calling patch_namespaced_custom_object with an empty name, causing an error and an unnecessary watch reconnect. Fix: guard against empty volume_name, log a warning, apply the label on the next reconcile. The RecurringJob is still created on the first event.
Bug 2 — HHMM format for start label. The original design used HH:MM for the start time. Discovered during Test 6 when kubectl label rejected 00:30 as an invalid label value. Fix: enforce HHMM format throughout — cron.py, labels.py, ConfigMap, and README all updated.
Bug 3 — Archive labels not copied to job at snapshot creation. When the archive workflow starts, the controller creates a snapshot and copies archive=true and archive-delete-after from the PVC to the RecurringJob in the same step. This copy was missing in the original implementation. Without it, the job had no archive labels until the backup completed — meaning if the PVC was deleted before the workflow finished, the orphan detection would see no archive=true on the job and delete it. Fix: copy archive labels to the job at snapshot creation time, not at completion time.
Bug 4 — RBAC missing snapshot and backup create permissions. The ClusterRole had read permissions on backups but not create permissions on snapshots or backups. The controller crashed the first time it tried to trigger an archive backup. Fix: add snapshots: create and backups: create to the ClusterRole.
Operational boundaries
The controller manages job existence and compliance — it does not monitor job execution. If Garage S3 is unavailable, Longhorn backup jobs will fail silently from the controller's perspective. Longhorn itself logs execution failures and the Longhorn UI shows failed jobs, but the controller has no visibility into whether a backup actually completed successfully.
To be explicit about what is and isn't automated:
Managed by the controller: job creation and updates, label compliance alerting, archive backup triggering, orphan detection and job cleanup.
Left to the operator: volume restores, execution monitoring, and final data and job deletion.
A controller crash or pod restart is handled cleanly. On startup the controller runs a full reconcile pass before entering the watch loop, so any events missed during downtime are caught immediately. No manual intervention is needed after a restart — state is always derived from the cluster, never held in memory.
One known observability gap: when a PVC is deleted without an archive label, the watch loop deletes the job immediately. Because the job is gone before the next full reconcile runs, the backup_pvc_orphaned metric never fires — the full reconcile only sets that metric when it finds a managed job whose source PVC is gone, but in this path the job has already been cleaned up. The deletion is silent from a metrics perspective. For an unintentional deletion the cleanup is correct; it just leaves no trace in the metrics.
The result
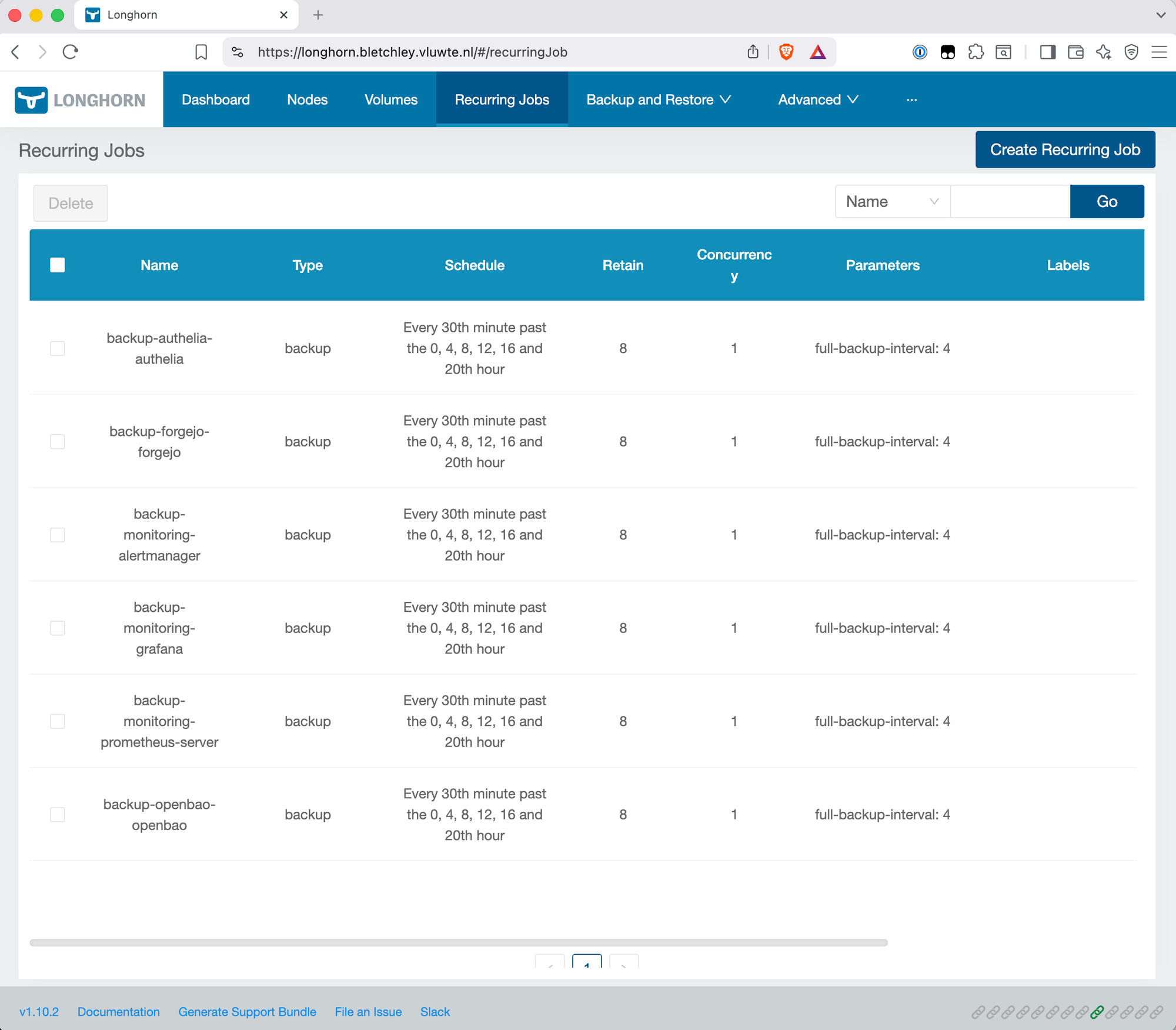
The controller is running on Bletchley at v0.10.0. Six Longhorn-backed PVCs are covered. Four manual jobs with auto-generated names are gone. The Prometheus metrics are live, the alert rules are loaded, and the first emails have been received and confirmed.
The backup loop is closed. New PVC gets labels, job exists within seconds. Label goes wrong, alert fires within minutes. PVC deleted without ceremony, job cleaned up immediately. PVC decommissioned properly, archive backup triggered, job retained, expiry alert follows. The system removes an entire class of human error — forgotten backups — while making failures explicit and observable.
What's Working Now
- ✅ Controller running in-cluster at v0.10.0
- ✅ All 6 Longhorn-backed PVCs labelled and managed
- ✅ 6 controller-managed RecurringJobs — consistent naming, consistent schedule
- ✅ 4 manual jobs with auto-generated names deleted
- ✅ Prometheus scraping
/metrics, all gauges live - ✅ All alert conditions routing to email via Alertmanager
- ✅ Archive workflow tested end-to-end
- ✅ Code published: github.com/vluwte/longhorn-backup-controller
- ⚠️
backup_pvc_orphanedmetric does not fire on watch-loop deletion — known limitation - ⚠️ Metrics lag up to 5 minutes behind watch events — acceptable given
for: 5malert duration
← Previous: Secret Management Part 4
Questions or suggestions? Leave a comment below or reach out at igor@vluwte.nl.