Prometheus Behind Traefik and Authelia: Closing the Last Ingress Gap
Two files close the Prometheus ingress gap — then a latent cert-manager bug surfaces. The ESO key name mismatch that renewal tests don't catch.
Introduction
Every service on the Bletchley cluster has a hostname, a TLS certificate, and Authelia protecting it — except one. Prometheus has been accessible only via kubectl port-forward, which means opening a terminal, running a command, and leaving it running for the duration of the session. Every time. It was a gap I knew about and kept deferring because the tunnel worked well enough and there was always something more pressing.
Closing it should have been a fifteen-minute job. Two files: one Ingress manifest and one line in the Authelia values. It was, in the end — but it surfaced a latent bug introduced during the OpenBao migration that had been sitting undetected for weeks. The fix was also one line, but finding it required working through the full cert-manager certificate issuance chain. That diagnostic path is worth documenting.
🏠 This is part of the Homelab Journey series - building a production Kubernetes cluster from scratch.
- Keeping the Cluster Current
- Prometheus Behind Traefik and Authelia: Closing the Last Ingress Gap (you are here)
The Two-File Change
The pattern for exposing a cluster service via Traefik with TLS and Authelia is well established at this point. Alertmanager got the same treatment in the Alertmanager post. The Prometheus ingress follows it exactly.
A new file in apps/monitoring/ingresses/ingress-prometheus.yaml:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prometheus
namespace: monitoring
annotations:
traefik.ingress.kubernetes.io/router.entrypoints: websecure
cert-manager.io/cluster-issuer: letsencrypt-production
traefik.ingress.kubernetes.io/router.middlewares: traefik-redirect-to-https@kubernetescrd,traefik-authelia@kubernetescrd
spec:
ingressClassName: traefik
rules:
- host: prometheus.bletchley.vluwte.nl
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-server
port:
number: 80
tls:
- hosts:
- prometheus.bletchley.vluwte.nl
secretName: prometheus-tls
And a two-line addition to apps/authelia/authelia-values.yaml:
- domain: "prometheus.bletchley.vluwte.nl"
policy: one_factor
No TLS secret to create manually. cert-manager reads the cert-manager.io/cluster-issuer annotation and the tls.secretName field together and provisions the certificate automatically, storing it in the named secret. Traefik reads the same secretName field to know which secret to load. The secret prometheus-tls does not exist before the Ingress is applied — cert-manager creates it.
Applied with:
kubectl apply -f apps/monitoring/ingresses/ingress-prometheus.yaml
helm upgrade authelia authelia/authelia -n authelia -f apps/authelia/authelia-values.yaml
The Unexpected Detour
Traefik logs an error immediately after applying the Ingress:
ERR Error configuring TLS error="secret monitoring/prometheus-tls does not exist"
ingress=prometheus namespace=monitoring providerName=kubernetes
This is expected — Traefik starts routing as soon as the Ingress is applied, but cert-manager hasn't finished issuing the certificate yet. The error resolves itself once the secret exists. The question is how long that takes.
Checking the certificate pipeline:
kubectl get certificate,certificaterequest,order,challenge -n monitoring
NAME STATE AGE
alertmanager-tls-1-1585379262 valid 27d
grafana-tls-2-1860064419 valid 49d
prometheus-tls-1-1846305707 pending 8m49s
Eight minutes and still pending. The Alertmanager and Grafana orders are valid from weeks ago. Something is wrong with this one.
kubectl describe challenge -n monitoring
Presented: false
Processing: true
Reason: get credential error: key not found "privateKey" in secret 'cert-manager/transip-secret'
State: pending
The TransIP webhook can't find the privateKey it needs to create the DNS-01 challenge TXT record.
Tracing the Root Cause
The cert-manager-webhook-transip chart uses the TransIP API to create _acme-challenge TXT records during DNS-01 validation. It reads a private key from a Kubernetes secret. The key name it expects — privateKey — is defined in the ClusterIssuer, not in external documentation:
kubectl get clusterissuer letsencrypt-production -o yaml
solvers:
- dns01:
webhook:
config:
privateKeySecretRef:
name: transip-secret
key: privateKey
The key: privateKey field is what the webhook looks for. Checking what the secret actually contains:
kubectl get secret transip-secret -n cert-manager -o jsonpath='{.data}' | python3 -m json.tool
{
"apiKey": "PRIVATE_KEY=="
}
The value is correct — it is the TransIP private key. The key name is wrong. The secret has apiKey where the webhook expects privateKey.
This was introduced during the OpenBao/ESO migration. The ExternalSecret in infra/certificates/externalsecret-transip.yaml was syncing the private key from OpenBao faithfully, but naming it apiKey in the resulting Kubernetes secret:
data:
- secretKey: apiKey # ← this is what lands in the Kubernetes secret
remoteRef:
key: cert-manager/transip
property: apiKey # ← this is the key name in OpenBao
The fix is changing secretKey — the output key name in the Kubernetes secret — from apiKey to privateKey. The remoteRef.property stays as apiKey because that is what it is called in OpenBao and that does not need to change.
data:
- secretKey: privateKey # ← fixed
remoteRef:
key: cert-manager/transip
property: apiKey
Applied from the infra/certificates/ directory:
kubectl apply -f externalsecret-transip.yaml
externalsecret.external-secrets.io/transip-secret configured
ESO resynced the secret immediately on apply. Verifying the secret now has the correct key:
kubectl get secret transip-secret -n cert-manager -o jsonpath='{.data}' | python3 -m json.tool
{
"privateKey": "PRIVATE_KEY=="
}
In case the secret does not immediately resync, you can run:
kubectl annotate externalsecret transip-secret -n cert-manager force-sync=$(date +%s) --overwrite
The secret is now correct but the pending challenge does not retry on its own. Deleting the order forces cert-manager to create a new one:
kubectl delete order prometheus-tls-1-1846305707 -n monitoring
order.acme.cert-manager.io "prometheus-tls-1-1846305707" deleted from monitoring namespace
cert-manager creates a new order immediately. Confirming the certificate is issued:
kubectl get certificate -n monitoring
NAME READY SECRET AGE
alertmanager-tls True alertmanager-tls 27d
grafana-tls True grafana-tls 49d
prometheus-tls True prometheus-tls 147m
Why Renewal Worked But New Issuance Didn't
The TransIP secret was migrated to OpenBao in Secret Management Part 1 and verified at the time by deleting the it-tools-tls certificate secret and watching cert-manager renew it:
kubectl delete secret it-tools-tls -n it-tools
kubectl get certificate it-tools-tls -n it-tools -w
NAME READY
it-tools-tls True
it-tools-tls False ← secret deleted, renewal triggered
it-tools-tls False ← DNS-01 challenge in progress
it-tools-tls True ← new certificate issued
That test passed. The certificate renewed successfully. The chain appeared complete.
It was not a sufficient test.
Certificate renewal reuses an existing ACME account and order flow in a way that happened not to hit the broken code path. New certificate issuance triggers a fresh DNS-01 challenge that calls the TransIP webhook directly — which is exactly where the key name mismatch breaks things. The bug was latent after the migration, undetectable by renewal testing alone, and only surfaced when Prometheus became the first new certificate requested after OpenBao was set up.
The correct validation test is to request a certificate for a hostname that has never had one before, or to delete the ACME order entirely and force a full re-issuance. A renewal test confirms the ACME account is valid and the secret exists; it does not confirm the webhook can authenticate with the upstream DNS provider.
The Authelia Rolling Update Snag
With the certificate sorted, the Authelia Helm upgrade triggered a rolling update — a new pod created to replace the old one. The new pod stayed in ContainerCreating:
authelia-79c698cfd7-lfz75 0/1 ContainerCreating 0 2m11s
The cause:
Warning FailedAttachVolume attachdetach-controller
Multi-Attach error for volume "pvc-f70b6bb3-..."
Volume is already used by pod(s) authelia-76bf74c4ff-ncnnd
Authelia's Longhorn PVC is RWO — ReadWriteOnce — meaning only one node can attach it at a time. The old pod holds the volume. The new pod cannot start until the old one releases it. Kubernetes is waiting for a clean handoff that isn't happening because both pods are on different nodes.
The fix is to scale to zero first, clearing all pods and releasing the volume, then scale back to one:
kubectl scale deployment authelia -n authelia --replicas=0
kubectl get pods -n authelia
NAME READY STATUS RESTARTS AGE
redis-8db4d4fc6-lgktk 1/1 Running 0 3d13h
kubectl scale deployment authelia -n authelia --replicas=1
kubectl get pods -n authelia
NAME READY STATUS RESTARTS AGE
authelia-79c698cfd7-4vslm 1/1 Running 0 40s
redis-8db4d4fc6-lgktk 1/1 Running 0 3d13h
This is a known characteristic of RWO volumes with single-replica deployments. The brief downtime during scale-to-zero is acceptable for Authelia — it is not in the critical path for cluster operation, and the scale cycle takes under a minute.
For single-replica deployments on RWO storage, setting strategy.type: Recreate in the Helm values automates this — the old pod is terminated before the new one starts, releasing the volume cleanly. Worth applying to Authelia, Grafana, and Forgejo before the next upgrade cycle.
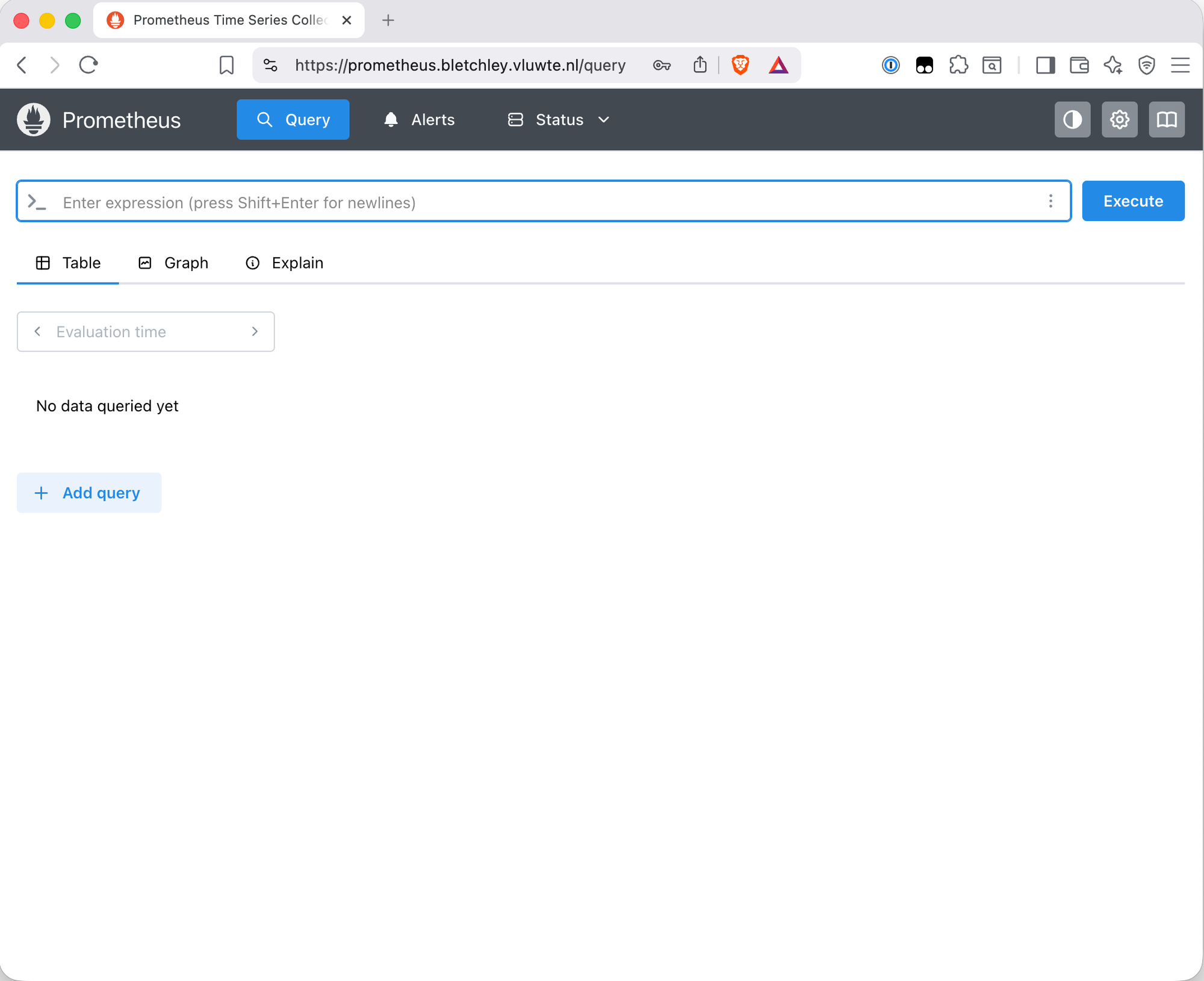
What's Working Now
- ✅
https://prometheus.bletchley.vluwte.nlaccessible via Traefik with a valid Let's Encrypt certificate - ✅ Authelia ForwardAuth protecting Prometheus — unauthenticated requests redirect to the login portal
- ✅ TransIP ExternalSecret key name corrected in code —
secretKey: privateKey - ✅ cert-manager → ESO → OpenBao chain validated end-to-end with a new certificate issuance
- ✅ No more
kubectl port-forwardto access Prometheus
Lessons Learned
- The ClusterIssuer tells you what key name is expected — no need to read webhook documentation.
kubectl get clusterissuer <name> -o yamlshows thekey:field underprivateKeySecretRefdirectly. - The full certificate pipeline in one command —
kubectl get certificate,certificaterequest,order,challenge -n <namespace>shows every stage at once and makes it immediately clear which step has stalled. kubectl describe challengeis the diagnostic endpoint — when an order is stuck pending, the challenge describe output gives the exact error. Everything above it in the chain is healthy; the challenge is where failures surface.- Renewal is not a sufficient validation test for the DNS-01 webhook — renewal reuses existing state and may succeed even when new issuance would fail. Test with a genuinely new certificate to validate the full chain.
- RWO volumes and rolling updates don't mix cleanly — for single-replica deployments on RWO storage, scale to zero before upgrading rather than relying on a rolling update that will stall waiting for volume handoff. Setting
strategy.type: Recreatein Helm values automates this for future upgrades.
← Previous: Keeping the Cluster Current
Questions or suggestions? Leave a comment below or reach out at igor@vluwte.nl.